6.1. Twitter: captura de datos y análisis de redes
6.1.4. Preguntas a resolver
6.1.4.1. ¿Quiénes están detrás de un trending topic?
¿Podrías decir si es dirigido o espontáneo?, ¿qué comunidades lo apoyan?, ¿hay redes de bots?
a. Qué análisis o visualización responde a la pregunta
A la hora de analizar una gran cantidad de tuits, un grafo (un conjunto de nodos y aristas) es la manera más eficaz y sencilla para entender cómo se configura una red. En este tipo de gráficos se representan los usuarios como los nodos y los retuits (republicación de un mensaje de otro usuario) como las aristas que relacionan un nodo y otro. Si el usuario A retuitea al usuario B, habrá una línea (arista) del punto A al B. Los retuits son el método más usado, pero también pueden usarse las menciones o las respuestas. Otra forma de analizar los datos es representar las relaciones de los usuarios que han usado ese hashtag según se sigan unos a otros.
b. Qué datos necesito y dónde los encuentro
Para poder analizar los tuits de un determinado hashtag hace falta, en primer lugar, obtenerlos. Para ello, el método más sencillo es usar la API de Twitter (Lo que siempre quiso saber del API de Twitter y nunca se atrevió a preguntar) para capturar esos tuits. Para hacer este ejercicio hemos usado el hashtag #xxxxx y durante xxxx horas hemos capturado xxx tuits. Existen otras opciones para analizar un hashtag en directo, como la herramienta Flocker, que descarga los tuits en directo y dibuja el grafo que se forma.
Para facilitar el proceso de captura con la API vamos a usar T-hoarder, el software libre que ha desarrollado Mariluz Congosto. Se trata de una aplicación ligera que corre en Python y que permite interactuar con la API de Twitter de una forma sencilla para obtener tuits y otras informaciones (perfiles de usuarios, seguidores…) y guardarlos en formatos fácilmente reutilizables (archivos de texto plano). T-hoarder puede usarse de dos modos:
- Usando el código disponible en github corriendo Python directamente en la consola. Accede al manual de instalación para Windows y Linux/Unix para más detalle.
- Mediante una máquina virtual en la que se accede a un entorno en el que se puede usar T-hoarder y Gephi. Es necesario usar el software Virtual box para hacer funcionar la máquina virtual. Descarga la máquina virtual (3,9GB) que viene preinstalada con T-hoarder_kit y Geph: https://www.dropbox.com/s/18gt69suptie5hw/ubuntumate1602_taller.ova (usuario: taller; contraseña: tallerdatos).

En la máquina virtual basta con hacer doble clic en el icono de T-hoarder para arrancar el programa.
Si corres directamente t-hoarder_kit en tu consola al directorio /scripts/ donde hayas descargado t-hoarder_kit y ejecuta ./t_hoarder_kit.sh.
En ambos casos te pedirá donde el archivo de «application keys»; vamos a ver cómo generarlo:
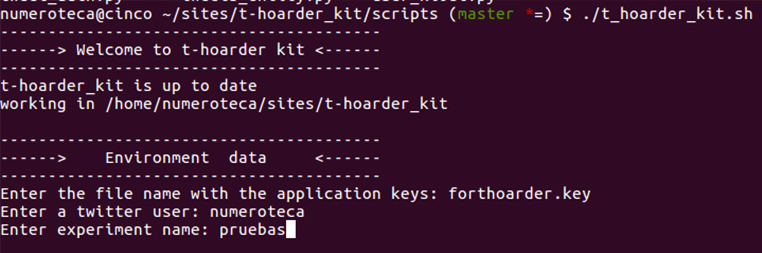
Generando Keys en Twitter Apps
Es necesario crear una aplicación con la que obtener el acceso a la API de Twitter. Ve a Twitter Apps para crear una nueva aplicación: https://apps.twitter.com. Para poder acceder necesitas crear un usuario de Twitter si no lo tienes ya.
Rellena los datos de la aplicación según se indica en la imagen:
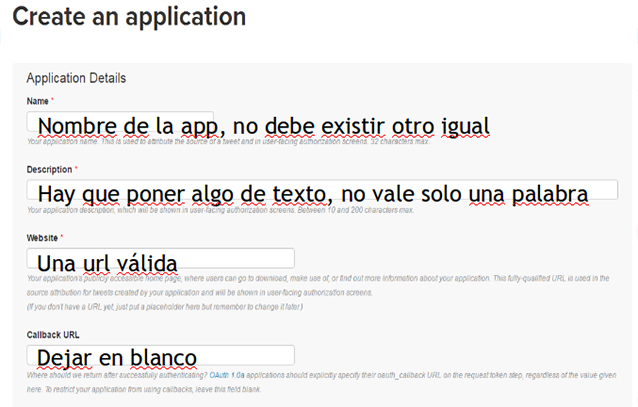
En la pestaña Keys and Access Tokens, copia el Consumer Key y el Consumer Secret:
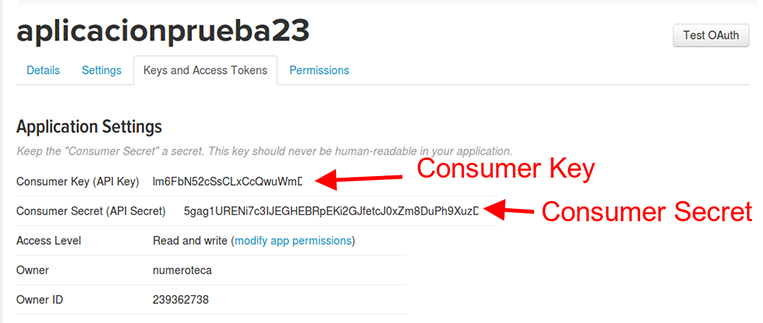
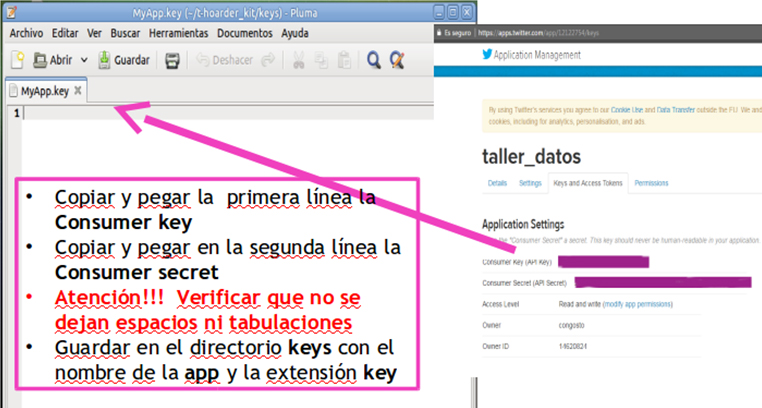
Crea un archivo de nombre forthoarder.key en el que en la primera línea esté la Consumer Key (API Key) y en la segunda el Consumer Secret (API Secret); quedará algo como esto:
W960clipfwefVxEdg jKt9GVQ3BHOq0Jp4hHIOlB6npoD8n5feL89ruE
Y sálvalo con el nombre forthoarder.key en el directorio /keys/ de tu instalación de t-hoarder. Utiliza una aplicación de edición de texto plano (notepad, gedit…).
Ya tienes todo listo para el siguiente paso.
Así debería quedar la estructura de carpetas:

En este caso las claves creadas son rest_001.key y taller_datos.key.
La aplicación en la consola te va preguntando y tienes que ir dando los datos. Los datos que pide al inicio son para el contexto del trabajo: se necesita una app, un usuario Twitter y un directorio de trabajo previamente creado para dejar los resultados.
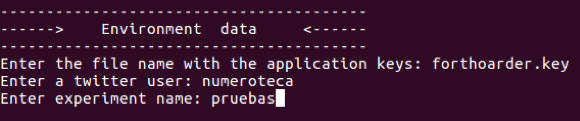
- Enter the file name with the application keys: forthoarder.key.
- Enter a twitter user: mi_user.
- Enter experiment name: pruebas.
Si estás utilizando la máquina virtual pon como usuario mi_user.
Donde forthoarder.key es el archivo con nuestras claves, numeroteca es el usuario con el que has creado la aplicación, y taller es el directorio que debes crear en la carpeta /store/. Puedes tener tantos experimentos como quieras; cada uno en su correspondiente directorio.
Si todo ha ido bien, deberíamos ver el siguiente menú:
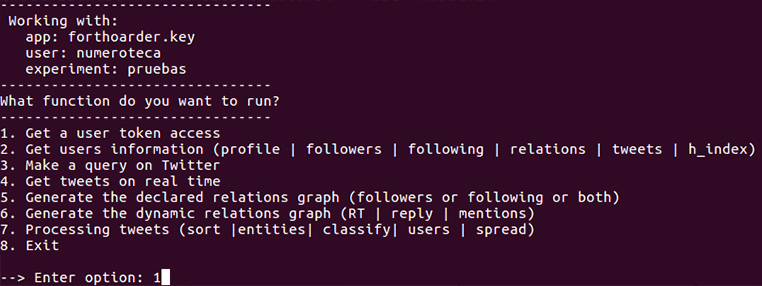
Seleccionamos la opción 1 para generar el permiso de nuestro t-hoarder_kit desde nuestra máquina. Esto abrirá el navegador que tengamos asignado por defecto; metemos nuestro usuario y password y nos dará un número de 7 cifras que tenemos que copiar y pegar en la aplicación:
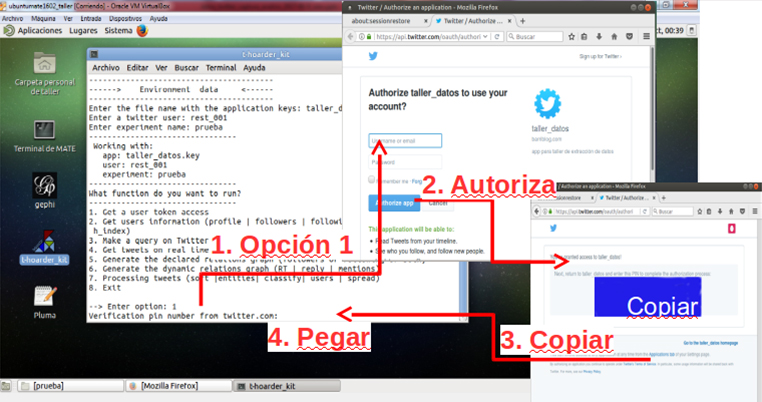
Si todo ha ido bien, veremos algo así en la consola:
Verification pin number from twitter.com: 6347239 Access token generado con éxito. Guardado en keys/numeroteca.key
Y se habrá generado un archivo numeroteca.key en nuestro directorio /keys.
Ya está todo listo para empezar a capturar datos.
Nota
T-hoarder no captura toda la información de los tuits (ver documentación, anatomía de un tuit) sino «id, user, … [completar]» y la almacena en archivos de texto plano (.txt). Otros software almacenan la información en bases de datos (postgress, SQL…), lo que dificulta su tratamiento y la capacidad para ser compartida de forma rápida y sencilla.
Elige la opción 3. Make a query on Twitter para descargar tuits de una búsqueda. Por ejemplo, si queremos descargar retroactivamente el hashtag #parlament (crea antes en la carpeta del experimento el archivo vacío parlament-tweets-query.txt):
--> Enter option: 3 Enter a query (allows AND / OR connectors): #parlament Enter output file name: parlament-tweets-query.txt /home/numeroteca/sites/t-hoarder_kit/store/pruebas/parlament-tweets-query.txt >>>>/home/numeroteca/sites/t-hoarder_kit/store/pruebas//parlament-tweets-query.txt file exists, do you want to append more tweets (y/n)?y
Si todo va bien verás algo como esto, el script que informa que los tuits se están capturando bien:
collected 0
{u'type': u'Point', u'coordinates': [-3.7058, 40.4203]}
remaing hits 179
collected 100
remaing hits 178
collected 200
remaing hits 177
collected 300
[...]
Si se quiere parar la captura de tuits, presionar ctrl + c.
Si abrimos el archivo store/pruebas/parlament-tweets-query.txt podemos ver los tuits capturados.
Otra opción es descargar los tuits en tiempo real con la streaming API; para ello, usa la opción 4. Get tweets on real time:
--> Enter option: 4 Enter input file name with the keywords separated by , : palabras_clave.txt
Se necesita un archivo de texto plano con las palabras clave para hacer la búsqueda de tuits. Por ejemplo, si quieres buscar el hashtag #parlament, el archivo solamente contendrá #parlament. Si quieres hacer búsquedas de otras palabras, sepáralas por comas. Prueba en Twitter sur bús
c. Qué herramientas uso para preparar los datos
Una vez que hemos obtenido los tuits, necesitamos convertirlos en un formato interpretable por Gephi, un software libre y muy extendido para generar grafos. T-hoarder de nuevo nos facilita convertir una serie de tuits en un archivo .gdf.
Antes de procesar los datos podemos limpiarlos y filtrarlos de falsos positivos; por ejemplo, si estamos capturando tuits sobre el Parlamento catalán, los que no hagan referencia a ese tema. Con herramientas como R o vi se podrían eliminar, por ejemplo, todos los tuits que contengan tal o cual palabra.
¿Qué hacer con la lista de tuits?
A partir de una lista de tuits se pueden extraer muchos análisis: usuarios más retuiteados, número de tuits por minuto/hora/día. A partir de los tuits se pueden obtener los id de los usuarios y con los usuarios puedo calcular sus relaciones (follower-following). Ojo: para obtener los following de cada usuario, ¡la API te da los following de 60 usuarios cada hora!
Según se procesen los tuits, se pueden obtener dos tipos de grafos:
- De relaciones declaradas (following y followers entre los usuarios del hashtag).
- De relaciones dinámicas (los que se retuitean).
Ambas son interesantes a la hora de analizar quién está detrás de un hashtag, pero para realizar la primera de ellas (relaciones declaradas) es necesario obtener nuevos datos: ¿a quién siguen los usuarios que usan ese hashtag? [ver siguiente pregunta].
Veamos paso a paso cómo generar el .gdf con t-hoarder:kit. Selecciona la opción 6. Generate the dynamic relations graph (RT | reply | mentions):
--> Enter option: 6 Enter input file name with the tweets (got from a query or in real time): parlament-tweets-query.txt.log Enter the relationship type (RT | reply | mention): RT Introduce top size (100-50000): 100 ------> Extracting relation RT -----> second pass format gdf type: top nodes: 100 generating gdf file type: all nodes: 5402 generating gdf file
El valor introducido en Introduce top size es para «podar» el grafo. Genera un subgrafo con los n nodos más activos y relevantes. Es por si el grafo es muy grande y no nos cabe en Gephi (es demasiado grande y el ordenador no puede manejarlo); podemos generar un grafo menor que no es lo mismo pero es representativo.
Si has analizado una lista de tuits y las relaciones establecidas son sus RT (retuit), se obtienen dos archivos:
- Los top RT: xxxxxxxx_top_RT.gdf. Es el grafo podado con los n usuarios (100 en nuestro caso) más retuiteados.
- Todos los RT: xxxxxxxx_all_RT.gdf.
Está todo listo para usar estos archivos en Gephi.
d. Qué herramientas uso para producir el análisis o la visualización
Una vez tenemos el archivo .gdf podemos emprender el penúltimo paso: crear el grafo.
Paso a paso de cómo hacer un grafo con Gephi
0) Instala y abre Gephi
Descarga https://gephi.org/users/download/.
Es un programa que funciona en Java; más que instalarlo, tienes que ejecutarlo cada vez. Desde la línea de comandos ve al directorio /bin de los que has descargado y ejecuta ./gephi. Lo más seguro es que para hacer esto tengas que darle permisos de ejecución al archivo.
![]()
Si estás en la máquina virtual, simplemente haz clic en el icono de Gephi del escritorio.
1) Genera un grafo
Abre el archivo xxxxxxxx_all_RT.gdf generado en el paso anterior.
Te preguntará si el grafo es dirigido, no dirigido o mixto («graph style»). Escogemos dirigido, ya que los RT tienen dirección: establecen una arista (flecha) del nodo del usuario que retuitea al originario autor del tuit.
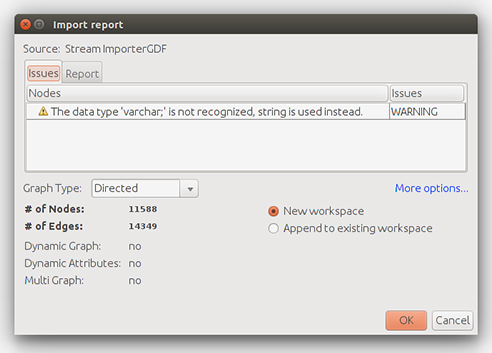
Esto me importa todos los nodos al espacio de trabajo.
Los nodos recién creados siempre toman esa forma cuadrada.
De la sección «Statistics» de la derecha, en el directorio Librariy -> Topology seleccionamos con doble clic «Giant component».
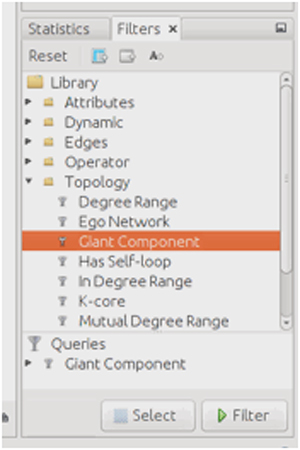
Ahora el filtro «Giant component» está en la lista de Queris. Si lo seleccionamos y hacemos clic en «Filter», estamos aplicando este filtro a nuestros datos.
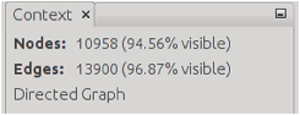
Ver que arriba a la derecha hemos reducido el número de nodos y aristas seleccionadas:
Ahora pasamos a la pestaña «Statistics» y ejecutamos el cálculo de «Modularity» (modularidad de la red) haciendo clic en Run:
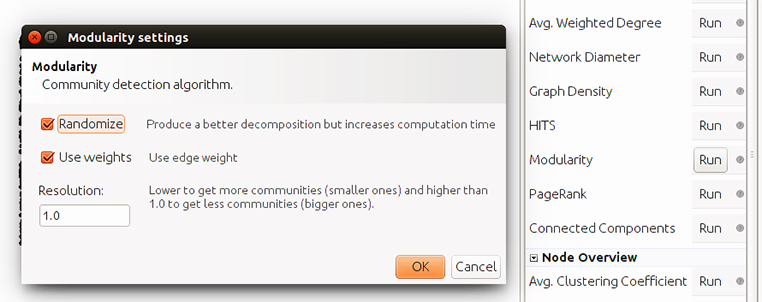
Nos da el resultado:
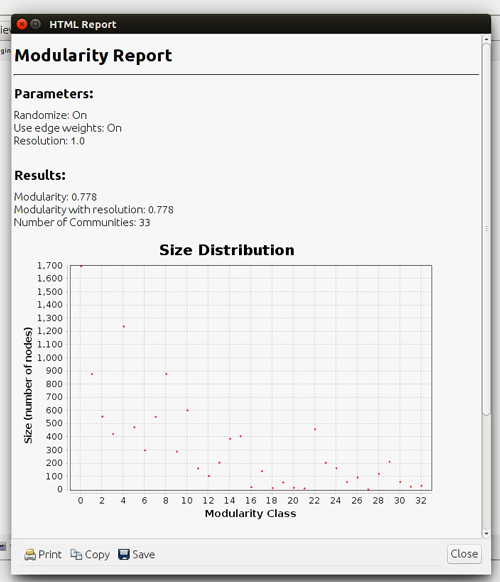
Ahora tenemos que seleccionar cómo se pintan los nodos. Elegimos colorearlos según la modularidad que acabamos de calcular (si vamos al modo de visualización de datos veremos que se ha añadido una columna con la modularidad). En la pestaña Appearance -> Nodes [paleta pintor] -> Partition selecciona Modularity Class.
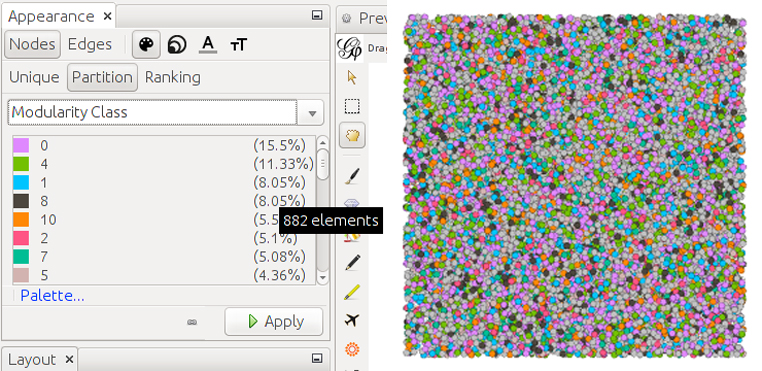
Puedes cambiar el color de cada categoría pulsando en el color de la leyenda.
Ahora los nodos están coloreados en función de la modularidad calculada.
En Preview Settings ->Settings selecciona la opción «parent» en «Border color» de los nodos:
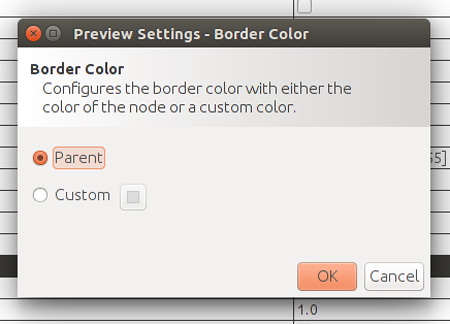
Ahora modificamos el tamaño de los nodos dependiendo de su «in-degree», que es el número de aristas que reciben, esto es, el número de RT que han recibido sus tuits. Para ello seleccionamos Apearance -> Nodes -> [tamaño] -> Ranking y seleccionamos In-Degree.
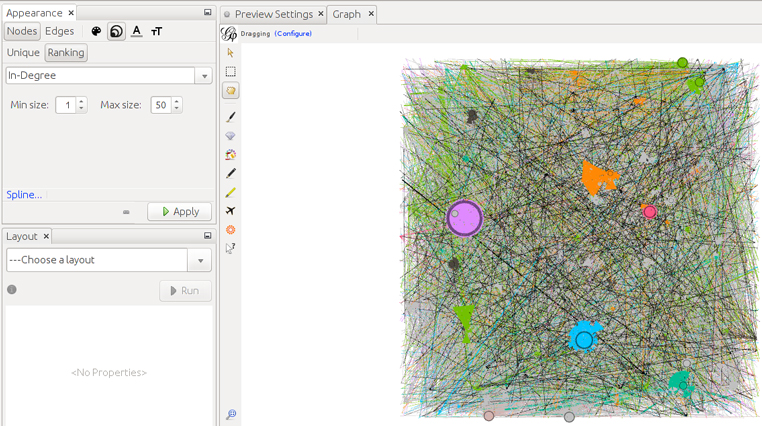
Ahora en «Layout» seleccionamos «Forceatlas 2» para reubicar la posición de los nodos y conseguir que se agrupen en relación con las comunidades detectadas de «modularidad».
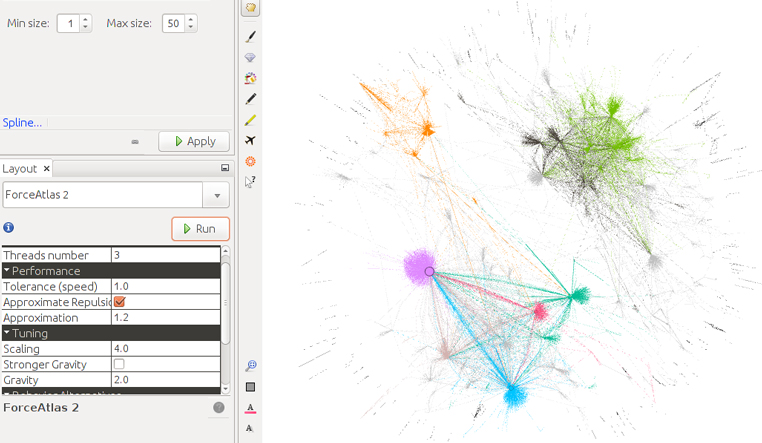
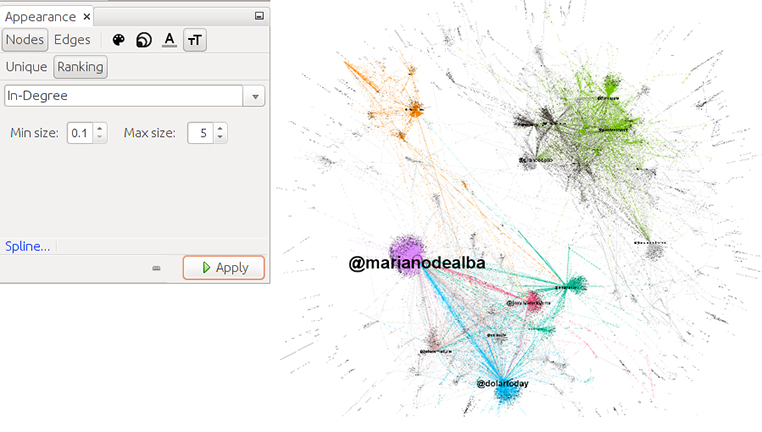
La «T» negra nos permite activar las etiquetas («labels») de los nodos.

La opción de tamaño de texto de Appearance -> Nodes -> [tamaño letras] -> Ranking nos deja seleccionar el tamaño mínimo y máximo de las etiquetas de los nodos en función de la variable, de nuevo, «in-degree». Selecciona de mínimo 1 y 50 de máximo. En Preview settings selecciona una tipografía de 5 puntos de tamaño.
Podemos controlar el color y grosor de las aristas en «Preview» settings. Elegimos «source» para ver de dónde vienen los RT, esto es, el color de la arista será el del retuiteador.
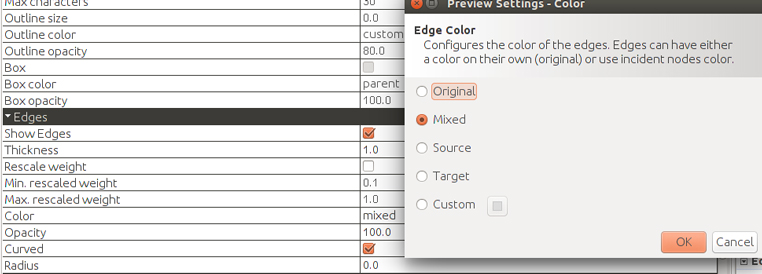
Estas son las opciones:
- SOURCE: The source node’s color.
- TARGET: The target node’s color.
- MIXED: An average of source and target color.
- CUSTOM: A custom color.
- ORIGINAL: The original edge color, if exists.
A veces, cuando hay muchos RT de un nodo a otro, Gephi no puede manejarlo bien y pinta triángulos o círculos. Se arregla marcando «reescalar pesos».
Es el momento de exportar, vamos al menú File -> Export -> SVG/PNG/PDF file… y seleccionamos si queremos un archivo vectorial (PDF o SVG) o imagen raster, de píxeles (PNG). En opciones, podemos cambiar el tamaño de la imagen y el margen.
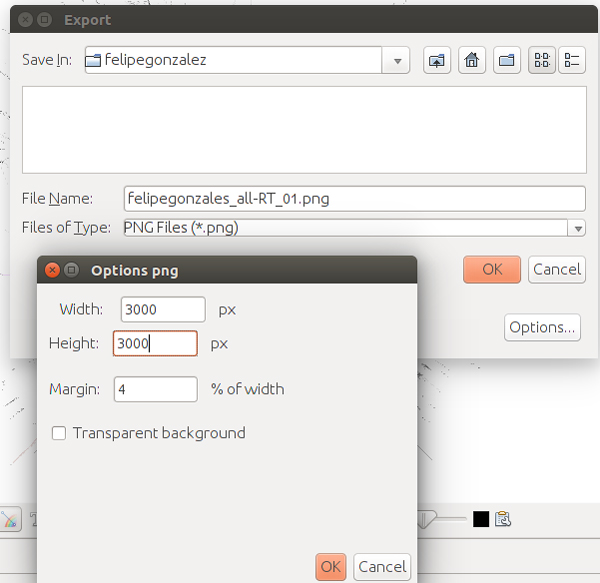
El proceso de exportación tendremos que realizarlo repetidas veces hasta que ajustemos el tamaño de los nodos y las etiquetas que deseemos.
Resultados
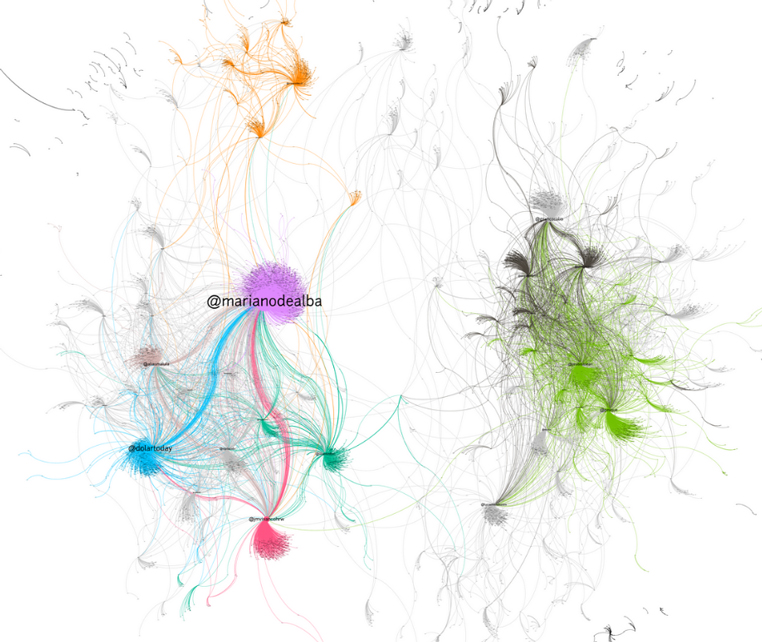
Grafo de la búsqueda «Felipe González»; se representan usuarios en esos tuits como nodos y las relaciones representadas como vértices son los RT entre ellos. Tuits descargados con search query de 2018-01-09 00:49:41 a 2018-01-16 12:43:37 un total de 17.597 tuits.
Grafo del hashtag #parlament, se representan usuarios en esos tuits como nodos y la relaciones representadas como vértices son los RT entre ellos. Tuits descargados con t-hoarder con search query de 2018-01-17 13:20:53 a 2018-01-17 17:20:34 y con streaming de 2018-01-17 18:20:50.308562 a 2018-01-17 19:11:03, un total de 14.779 tuits.
 e. Cómo presento la información para hacer un relato inteligible
e. Cómo presento la información para hacer un relato inteligible
Probablemente, el gráfico resultante no sea lo suficientemente explicativo para responder a la pregunta inicial. Un grafo sin una leyenda que explique los colores, sin un texto que lo acompañe, sin un titular o destacado que lo explique no vale como respuesta. Cada vez se usan más los grafos en la prensa, pero es necesario aclarar qué es lo que representan los puntos y líneas que estamos viendo. Sirva esta aclaración como ejemplo:
«Los grafos se han generado tomando los retuits como elemento de conexión de los usuarios. Cada nodo es un usuario y cada arco es una conexión entre retuiteador y retuiteado. El tamaño de los nodos es directamente proporcional al número de RT recibidos».
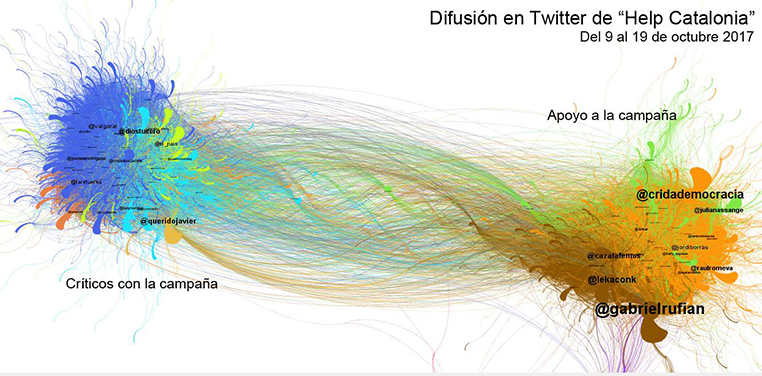
Fuente: http://www.barriblog.com/2017/10/hilo-difusion-la-campana-help-catalonia-twitter/.
Para ello, tenemos que contar y acompañar al grafo o grafos resultantes de todos estos elementos y añadir también la documentación de cómo se han obtenidos los datos y realizado el/los gráficos. Si has capturado datos por un largo periodo de tiempo, quizás necesites realizar diferentes grafos según las fases de propagación del hashtag.
Puedes usar los filtros que ofrece Gephi para mostrar las diferentes categorías (modularity) que se usan para colorear los gráficos para analizar la composición de esas redes y de qué habla cada una de ellas. Este tipo de filtros permite dejar solo activos los usuarios de una o más categorías.
Paso a paso:
- Elige título.
- Escribe párrafo explicativo/introductorio.
- Añade gráficos que lo acompañen.
Para cada uno de los grupos detectados (modularity), podemos calcular las palabras más usadas (bigramas y trigramas con databasic.io) y/o hacer un ranking o una nube con ellas. T-hoarder ofrece también la posibilidad de calcular las palabras más populares con la opción 7. Processing tweets (Entities). A partir de lista de tuits. Las palabras asociadas a cada grupo pueden ayudar a entender el grafo:
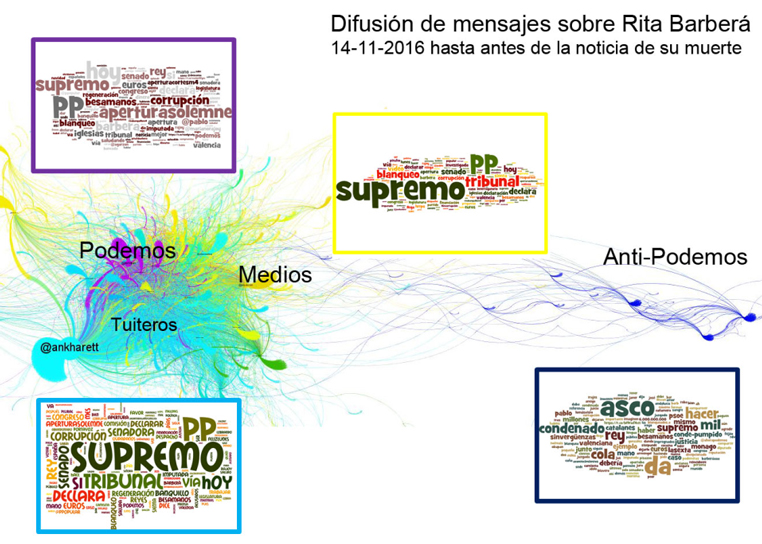
Fuente: http://www.barriblog.com/2016/11/despues-la-muerte-rita-barbera-twitter/.
Ejemplos de análisis con esta metodología:
- Así se viralizó Tabarnia en redes sociales. Mariluz Congosto, 2018.
- Difusión de la campaña «Help Catalonia» en Twitter.
Nota
Puedes descargar el .gdf para replicar este ejercicio:
6.1.4.2. ¿Cómo se relacionan los seguidores de una cuenta de Twitter?
a. Qué análisis o visualización responde a la pregunta
Un grafo.
b. Qué datos necesito y dónde los encuentro
Crea un listado con los usuarios que han publicado un determinado hashtag (pregunta anterior): ¿cómo se obtiene esa lista? T-hoarder_kit te permite, con la opción 7.Processing tweets y usando las opciones entity (que extrae los usuarios más retuiteados, los más mencionados y los más activos), obtener un fichero con la lista de usuarios. Hay que limpiar el archivo generado ya que tiene asociadas otras variables, y lo que necesitamos es un archivo con cada nombre de usuario en una línea. Lo siguiente es obtener los perfiles (profiles) de esos usuarios: 2.Get users information escribe opción profile. Esto genera un archivo de nombre xxxxx_profiles.txt que contiene todos los perfiles.
A partir de esa lista de perfiles se pueden calcular sus relaciones (follower-following). Atención: para obtener los followers-following de cada usuario, la API los proporciona a una velocidad de 60 usuarios cada hora. Por lo tanto, para analizar la relación entre 1.000 usuarios, nos llevaría 16,6 horas. Con el archivo .gdf generado pasamos al siguiente paso. Por tanto, antes de empezar a ver las relaciones entre un grupo de usuarios de un determinado hashtag, podemos seleccionar los usuarios según un criterio (actividad o relevancia) para hacer listas de usuarios más pequeñas y, por ejemplo, estudiar cómo están relacionados los 100 usuarios más mencionados o los 100 usuarios más activos.
Tienes que hacer un grafo de relaciones declaradas (following y followers entre los usuarios del hashtag).
c. Qué herramientas uso para preparar los datos
No aplicable. El archivo .gdf generado ya es válido para el siguiente paso.
d. Qué herramientas uso para producir el análisis o la visualización
Para generar el grafo seguimos el procedimiento descrito en el ejercicio anterior, con la diferencia de que ahora tendremos muchos menos nodos que en un grafo de RT. El layout «forceatlas» funciona mejor para menos nodos que el Forceatlas2.
e. Cómo presento la información para hacer un relato inteligible
Lo mismo del ejercicio anterior.
Ejemplo de análisis con metodología similar
- Digital Humanities on Twitter, a small-world? Martin Grandjean, 2015.
- Gregorio Morán, una columna vacía. Mariluz Congosto, 2017.
Puedes descargar el .gdf con las relaciones entre usuarios para replicar el ejercicio: gregoriomoran_users_profiles.gdf.