6.1. Twitter: captura de dades i anàlisi de xarxes
6.1.4. Preguntes a resoldre
6.1.4.1. Qui hi ha darrere d’un trending topic?
Podries dir si és dirigit o espontani? Quines comunitats el recolzen? Hi ha xarxes de bots?
a. Quina anàlisi o visualització respon la pregunta?
A l’hora d’analitzar una gran quantitat de piulades, un graf (un conjunt de nodes i arestes) és la manera més eficaç i senzilla per entendre com es configura una xarxa. En aquest tipus de gràfics, els usuaris es representen com a nodes i les repiulades (la republicació d’un missatge d’un altre usuari) es representen com les arestes que relacionen dos nodes. Si l’usuari A repiula un missatge de l’usuari B, hi haurà una línia (aresta) que anirà del punt A al punt B. Les repiulades són el mètode més usat, però també es poden utilitzar-se les mencions o les respostes. Una altra manera d’analitzar les dades és representar les relacions dels usuaris que han usat aquesta etiqueta segons si es segueixen entre ells.
b. Quines dades necessito i on les puc trobar?
Per poder analitzar les piulades d’una etiqueta en concret, en primer lloc cal obtenir-les. El mètode més senzill per capturar aquestes piulades és usar l’API de Twitter (Tot allò que sempre va voler saber de l’API de Twitter i mai es va atrevir a preguntar). Per fer aquest exercici hem usat l’etiqueta #xxxxx, i durant xxxx hores hem capturat xxx piulades. Existeixen altres opcions per analitzar una etiqueta en directe, com ara l’eina Flocker, que descarrega les piulades en directe i dibuixa el graf que es formen.
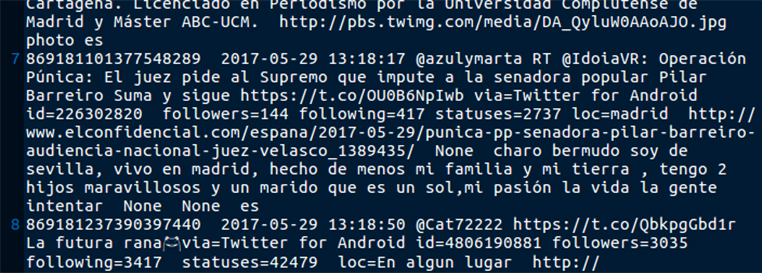
Per facilitar el procés de captura amb l’API utilitzarem T-hoarder, el programari lliure que ha desenvolupat Mariluz Congosto. Es tracta d’una aplicació lleugera que corre en Python i que permet interactuar amb l’API de Twitter d’una manera senzilla per obtenir piulades i altres informacions (perfils d’usuaris, seguidors, etc.) i guardar-les en formats fàcilment reutilitzables (arxius de text pla). T-hoarder es pot utilitzar de dues maneres:
- Usant el codi disponible a Github, executant Python directament a la consola. Accedeix al manual d’instal·lació per Windows i Linux/Unix per més detalls.
- Mitjançant una màquina virtual que permet accedir a un entorn en el que es pot usar T-hoarder i Gephi. És necessari usar el programari Virtual Box per fer funcionar la màquina virtual. Descarrega la màquina virtual (3,9GB) que ve preinstalada amb T-hoarder_kit i Geph: https://www.dropbox.com/s/18gt69suptie5hw/ubuntumate1602_taller.ova (usuari: taller; contrasenya: tallerdatos).

A la màquina virtual només cal fer doble clic en la icona de T-hoarder per arrencar el programa.
Si executes directament t-hoarder_kit en la teva consola, ves al directori /scripts/ on hagis baixat t-hoarder_kit i executa ./t_hoarder_kit.sh.
En ambdós casos et demanarà on és el fitxer application keys. Vegem com generar-lo:
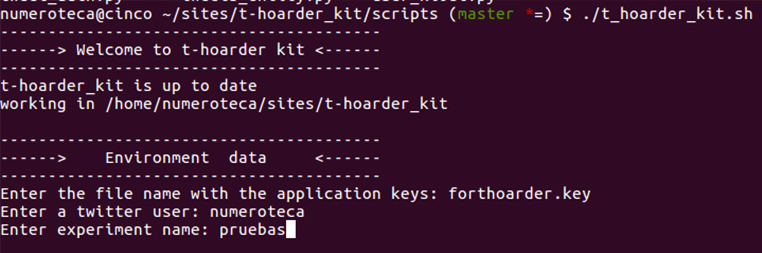
Generar Keys en Twitter Apps
Cal crear una aplicació que ens permeti accedir a l’API de Twitter. Ves a Twitter Apps per crear una nova aplicació: https://apps.twitter.com. Per poder accedir-hi cal crear un usuari de Twitter.
Omple les dades de l’aplicació segons s’indica a la imatge:
A la pestanya Keys and Access Tokens, copia la Consumer Key i el Consumer Secret:
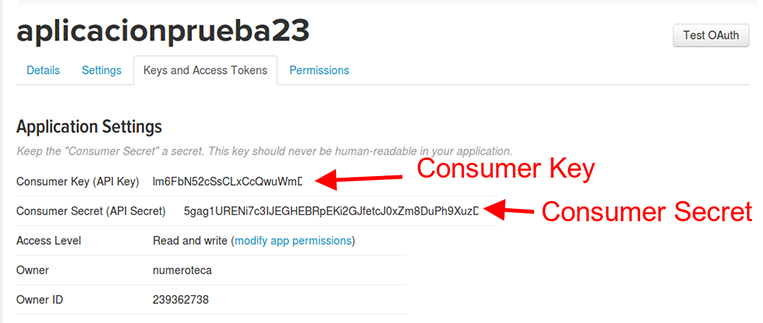
Crea un arxiu amb el nom forthoarder.key que inclogui la Consumer Key (API Key) en la primera línia i el Consumer Secret (API Secret) en la segona. El resultat serà semblant a això:
W960clipfwefVxEdg jKt9GVQ3BHOq0Jp4hHIOlB6npoD8n5feL89ruE
I guarda’l amb el nom forthoarder.key en el directori /keys/ de la teva instal·lació de T-hoarder. Utilitza una aplicació d’edició de text pla (Notepad, Gedit, etc.).
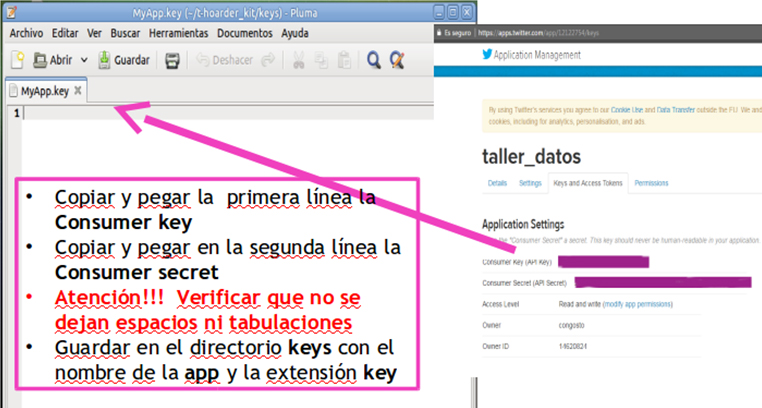
Ja ho tens tot llest per al següent pas.
L’estructura de carpetes hauria de quedar així:

En aquest cas, les claus creades són rest_001.key i taller_datos.key.
A la consola, l’aplicació et farà preguntes i hauràs d’introduir-hi les les dades. Les dades que demana a l’inici són per al context del treball: es necessita una app, un usuari Twitter i un directori de treball prèviament creat per deixar-hi els resultats.
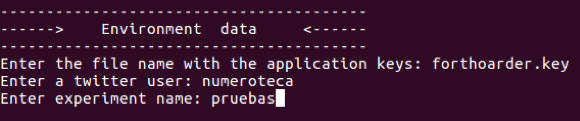
- Enter the file name with the application keys: forthoarder.key.
- Enter a twitter user: mi_user.
- Enter experiment name: pruebas.
Si estàs utilitzant la màquina virtual, posa com a usuari mi_user.
On forthoarder.key és l’arxiu amb les nostres claus, numeroteca és l’usuari amb el que has creat l’aplicació, i taller és el directori que has de crear a la carpeta /store/. Pots tenir tants experiments com vulguis, cadascun en el seu directori corresponent.
Si tot ha anat bé, hauríem de veure el menú següent:
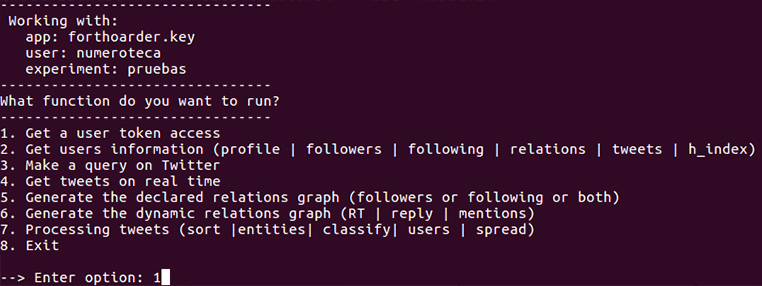
Seleccionem l’opció 1 per generar el permís del nostre T-hoarder_kit des de la nostra màquina. Això obrirà el navegador que tinguem assignat per defecte. Introduïm el nostre usuari i la nostra contrasenya, i obtindrem un nombre de 7 xifres que hem de copiar i enganxar a l’aplicació:
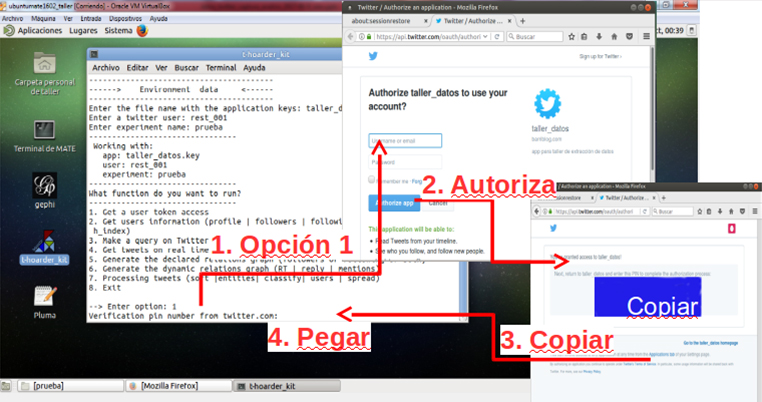
Si tot ha anat bé, a la consola hi veurem alguna cosa semblant a això:
Verification pin number from twitter.com: 6347239 Access token generado con éxito. Guardado en keys/numeroteca.key
I s’haurà generat un arxiu numeroteca.key en el nostre directori /keys.
Ja està tot llest per començar a capturar dades.
Nota
T-hoarder no captura tota la informació de les piulades (veure documentació, anatomia d’una piulada) sinó «id, user, … [completar]» i l’emmagatzema en arxius de text pla (.txt). Altres programaris emmagatzemen la informació en bases de dades (Postgres, SQL…), la qual cosa dificulta el seu tractament i la capacitat de compartir-la de forma ràpida i senzilla.
Tria l’opció 3. Make a query on Twitter per descarregar piulades d’una cerca. Per exemple, si volem descarregar retroactivament l’etiqueta #parlament (abans, crea l’arxiu buit parlament-tweets-query.txt a la carpeta de l’experiment):
--> Enter option: 3 Enter a query (allows AND / OR connectors): #parlament Enter output file name: parlament-tweets-query.txt /home/numeroteca/sites/t-hoarder_kit/store/proves/parlament-tweets-query.txt >>>>/home/numeroteca/sites/t-hoarder_kit/store/proves//parlament-tweets-query.txt file exists, do you want to append more tweets (y/n)?y
Si tot va bé, veuràs alguna cosa semblant a això, l’script que informa que les piulades s’estan capturant bé:
collected 0
{u'type': u'Point', u'coordinates': [-3.7058, 40.4203]}
remaing hits 179
collected 100
remaing hits 178
collected 200
remaing hits 177
collected 300
[...]
Si es vol parar la captura de les piulades, prémer ctrl + c.
Si obrim el fitxer store/proves/parlament-tweets-query.txt podrem veure les piulades capturats.
Una altra opció és descarregar les piulades en temps real amb la streaming API. Per fer-ho, usa l’opció 4. Get tweets on real time:
--> Enter option: 4 Enter input file name with the keywords separated by , : palabras_clave.txt
Per fer la cerca de piulades cal un fitxer de text pla amb les paraules clau. Per exemple, si vols buscar l’etiqueta #parlament, el fitxer només contindrà #parlament. Si vols fer cerques d’altres paraules, separa-les amb comes. Prova-ho a Twitter sur bús
c. Quines eines he d’utilitzar per preparar les dades?
Quan ja haguem obtingut les piulades, necessitarem convertir-les a un format interpretable per Gephi, un programari per generar grafs que és lliure i està molt estès. Una vegada més, T-hoarder ens facilita convertir una sèrie de piulades en un arxiu .gdf.
Abans de processar les dades podem netejar-les i filtrar-les de falsos positius. Per exemple, si estem capturant piulades sobre el Parlament de Catalunya, podrem filtrar les piulades que no facin referència a aquest tema. Amb eines com ara R o Vi es poden eliminar, per exemple, totes les piulades que continguin una paraula en concret.
Què es pot fer amb la llista de piulades?
A partir d’una llista de piulades es poden extreure moltes anàlisis: els usuaris més repiulats, el nombre de piulades per minut, hora o dia, etc. A partir de les piulades es poden obtenir els ID dels usuaris, i amb els usuaris es poden calcular les seves relacions (follower-following). Compte: per obtenir els following de cada usuari, l’API et dona els following de 60 usuaris cada hora!
Segons com es processin les piulades, es poden obtenir dos tipus de grafs:
- De relacions declarades (following i followers entre els usuaris de l’etiqueta).
- De relacions dinàmiques (els que es repiulen).
Ambdues són interessants a l’hora d’analitzar qui hi ha darrere d’una etiqueta, però per realitzar el primer graf (relacions declarades) és necessari obtenir noves dades: a qui segueixen els usuaris que usen aquesta etiqueta? [Veure la pregunta següent].
Vegem pas a pas com generar el .gdf amb T-hoarder:_kit. Selecciona l’opció 6. Generate the dynamic relations graph (RT | reply | mentions):
--> Enter option: 6 Enter input file name with the tweets (got from a query or in real time): parlament-tweets-query.txt.log Enter the relationship type (RT | reply | mention): RT Introduce top size (100-50000): 100 ------> Extracting relation RT -----> second pass format gdf type: top nodes: 100 generating gdf file type: all nodes: 5402 generating gdf file
El valor introduït a Introduce top size és per «podar» el graf. Genera un subgraf amb els n nodes més actius i rellevants. Això és útil quan el graf és molt gran i no hi cap a Gephi (és massa gran i l’ordinador no pot manejar-lo). En aquests casos podem generar un graf més petit que no és el mateix però és representatiu del graf original.
Si has analitzat una llista de piulades i les relacions establertes són els seus RT (repiulades), obtindràs dos fitxers:
- Els topRT : xxxxxxxx_top_RT.gdf. És el graf podat amb els n usuaris (en el nostre cas, 100) més repiulats.
- Tots els RT: xxxxxxxx_all_RT.gdf.
Està tot llest per usar aquests fitxers a Gephi.
d. Quines eines es poden utilitzar per produir l’anàlisi o la visualització?
Quan tinguem l’arxiu .gdf podrem fer el penúltim pas: crear el graf.
Com fer un graf amb Gephi pas a pas
0) Instal·la Gephi i obre’l
Descarrega https://gephi.org/users/download/.
És un programa que funciona amb Java. Més que instal·lar-lo, cal executar-lo cada vegada. Des de la línia de comandaments, ves al directori /bin que has descarregat i executa ./gephi. El més segur és que per fer-ho hagis de donar permisos d’execució a l’arxiu.
![]()
Si fas servir la màquina virtual, simplement fes clic en la icona de Gephi que hi ha a l’escriptori.
1) Genera un graf
Obre l’arxiu xxxxxxxx_all_RT.gdf que has generat en el pas anterior.
Et preguntarà si el graf és dirigit, no dirigit o mixt (graph style). Escollirem dirigit, atès que els RT tenen adreça: estableixen una aresta (fletxa) del node de l’usuari que repiula a l’autor original de la piulada.
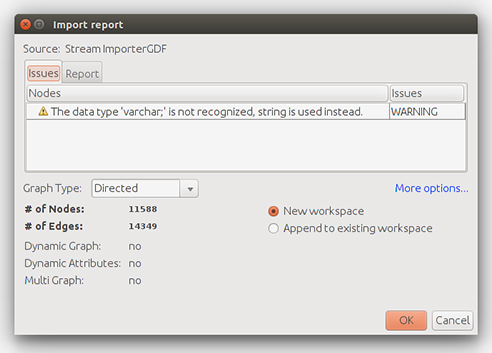
Això importa tots els nodes a l’espai de treball.
Els nodes creats recentment sempre tenen aquesta forma quadrada.
A la secció Statistics de la dreta, en el directori Library -> Topology, seleccionem amb doble clic Giant component.
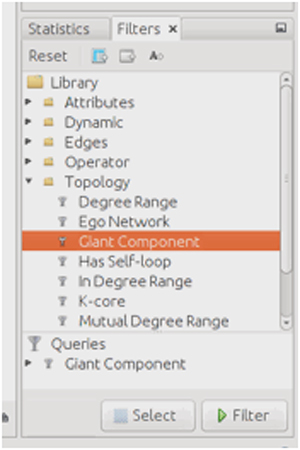
Ara el filtre Giant component és a la llista de Queries. Si el seleccionem i fem clic a Filter, apliquem aquest filtre a les nostres dades.
Vegeu que a dalt a la dreta hem reduït el nombre de nodes i arestes seleccionades:
Ara passem a la pestanya Statistics i executem el càlcul de Modularity (modularitat de la xarxa) fent clic a Run:
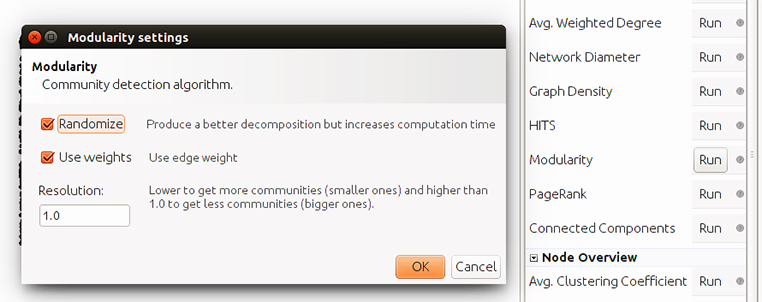
Obtenim el resultat següent:
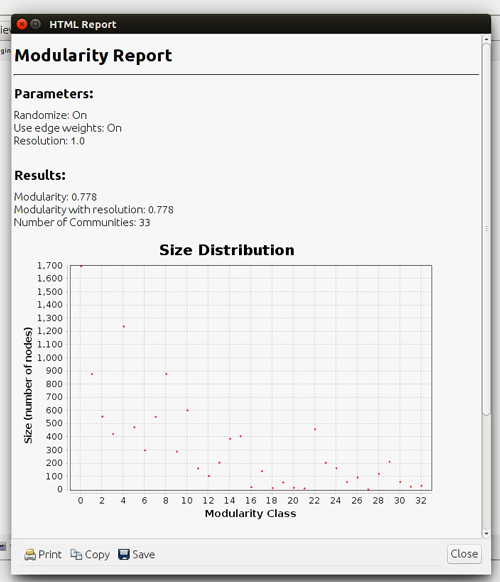
Ara hem de seleccionar com es pinten els nodes. Triem acolorir-los segons la modularitat que acabem de calcular (si anem a la manera de visualització de dades veurem que s’ha afegit una columna amb la modularitat). A la pestanya Appearance -> Nodes [paleta pintor] -> Partition, selecciona Modularity Class.
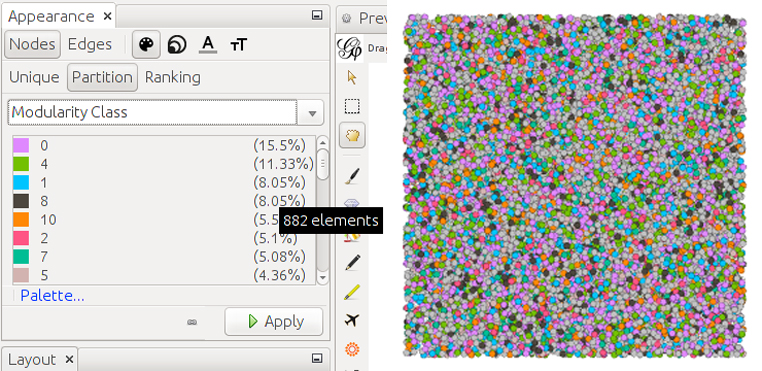
Pots canviar el color de cada categoria prement en el color de la llegenda.
Ara els nodes estan acolorits en funció de la modularitat calculada.
A Preview Settings ->Settings, selecciona l’opció Parent a Border color dels nodes:
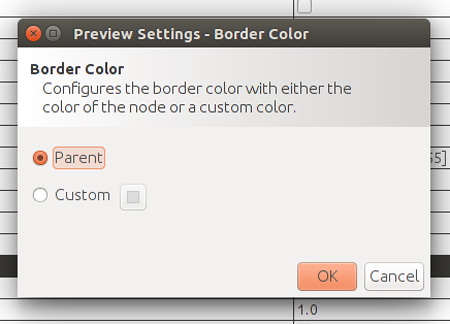
Ara modifiquem la grandària dels nodes segons del seu In-degree, que és el nombre d’arestes que reben, això és, el nombre de RT que han rebut les seves piulades. Per fer-ho seleccionem Apearance -> Nodes -> [tamaño] -> Ranking i seleccionem In-Degree.
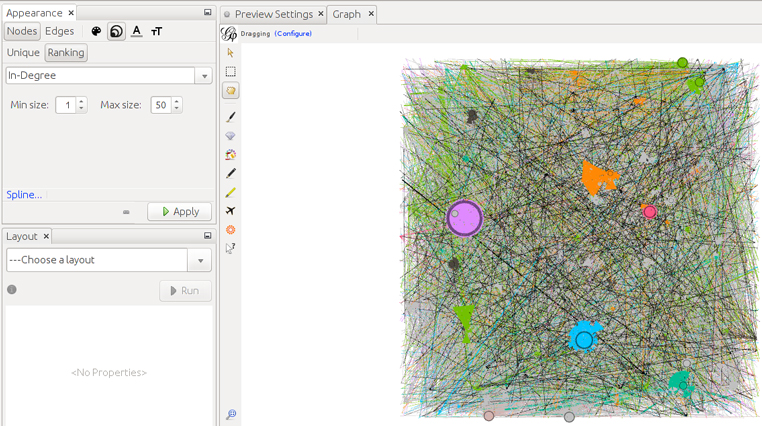
Ara, a Layout, seleccionem Forceatlas 2 per tornar a ubicar la posició dels nodes i aconseguir que s’agrupin en relació amb les comunitats detectades de modularitat.
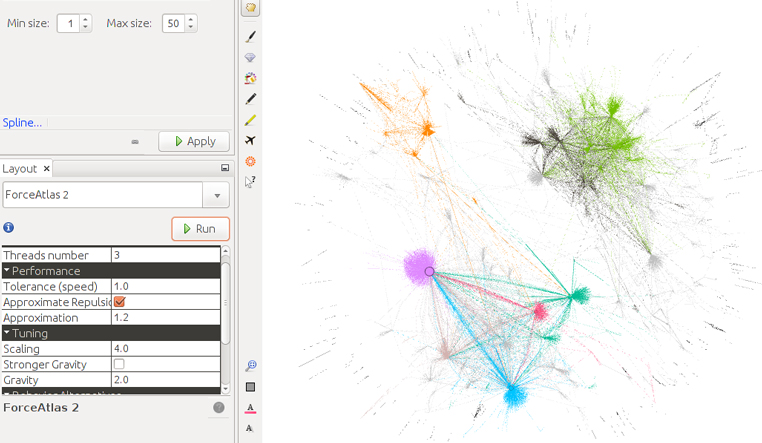
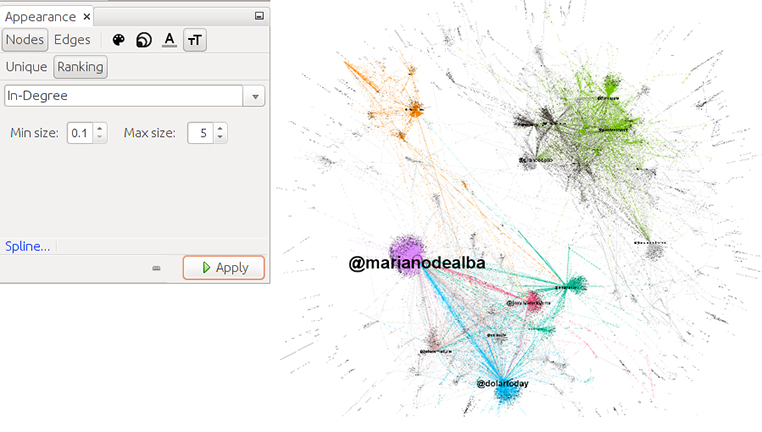
La T negra ens permet activar les etiquetes (labels) dels nodes.

L’opció de grandària de text d’Appearance -> Nodes -> [tamaño letras] -> Ranking ens permet seleccionar la grandària mínima i màxima de les etiquetes dels nodes en funció, una vegada més, de la variable In-degree. Selecciona 1 de mínim i 50 de màxim. A Preview settings, selecciona una tipografia de 5 punts de grandària.
Podem controlar el color i el gruix de les arestes des de Preview settings. Triem Source per veure d’on vénen els RT, és a dir, el color de l’aresta serà el de l’usuari que repiula.
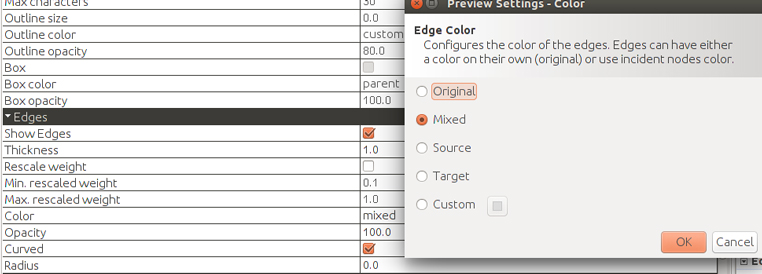
Aquestes són les opcions:
- SOURCE: The source node’s color.
- TARGET: The target node’s color.
- MIXED: An average of source and target color.
- CUSTOM: A custom color.
- ORIGINAL: The original edge color, if exists.
De vegades, quan hi ha molts RT d’un node a un altre, Gephi no pot manejar-ho bé i pinta triangles o cercles. Això es pot resoldre marcant «reescalar pesos».
Ha arribat el moment d’exportar: anem al menú File -> Export -> SVG/PNG/PDF file… i seleccionem si volem un arxiu vectorial (PDF o SVG) o una imatge rasteritzada, de píxels (PNG). A les opcions podem canviar la grandària i el marge de la imatge.
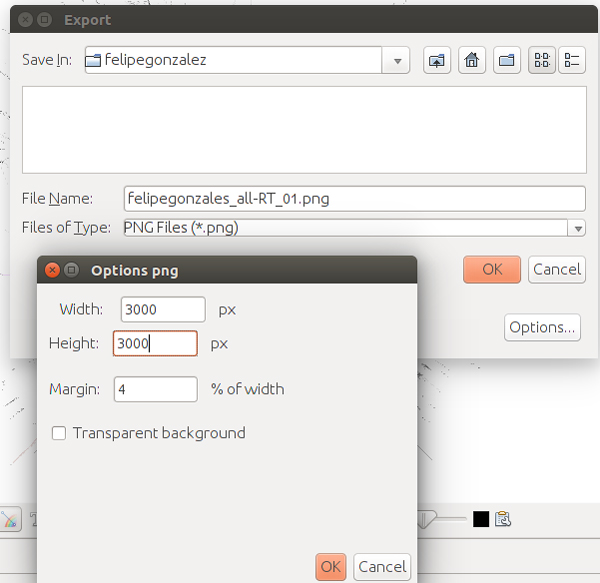
Haurem de realitzar el procés d’exportació repetides vegades fins que ajustem la grandària dels nodes i les etiquetes que desitgem.
Resultats
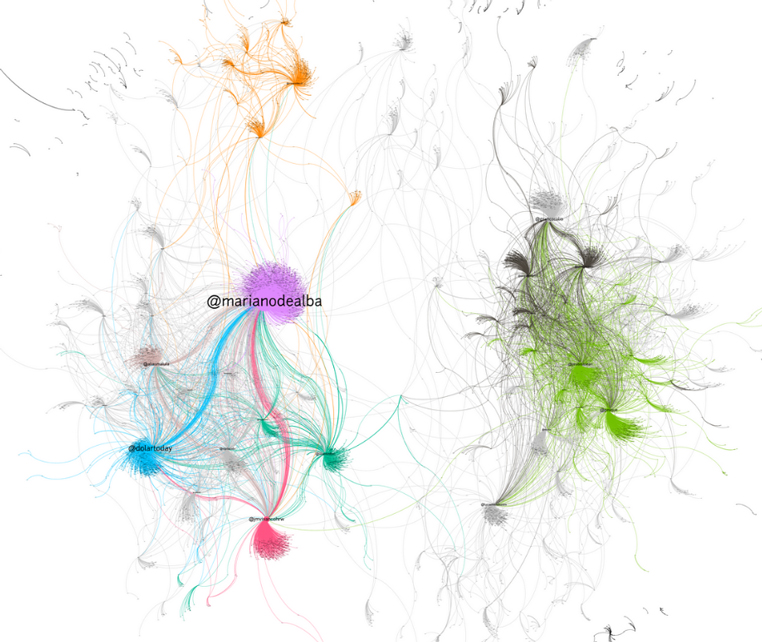
Graf de la cerca «Felipe González»: es representen els usuaris d’aquestes piulades com a nodes, mentre que les relacions representades com a vèrtexs són els RT entre ells. Piulades descarregades amb search query des de 2018-01-09 00:49:41 fins a 2018-01-16 12:43:37: un total de 17.597 piulades.
Graf de l’etiqueta #parlament: es representen els usuaris d’aquestes piulades com a nodes, mentre que les relacions representades com a vèrtexs són els RT entre ells. Piulades descarregades amb T-hoarder, amb search query des de 2018-01-17 13:20:53 fins a 2018-01-17 17:20:34 i amb streaming des de 2018-01-17 18:20:50.308562 fins a 2018-01-17 19:11:03: un total de 14.779 piulades.
 e. Com presento la informació per fer un relat intel·ligible?
e. Com presento la informació per fer un relat intel·ligible?
Es probable que el gràfic resultant no sigui prou explicatiu per respondre la pregunta inicial. Un graf sense una llegenda que expliqui els colors, sense un text que l’acompanyi o sense un titular o un destacat que l’expliqui no és una resposta vàlida. Els grafs s’utilitzen cada vegada més en la premsa, però és necessari aclarir què representen els punts i línies que estem veient. Aquest aclariment pot servir a tall d’exemple:
«Els grafs s’han generat prenent les repiulades com a element de connexió dels usuaris. Cada node és un usuari i cada arc és una connexió entre l’usuari que repiula i l’usuari repiulat. La grandària dels nodes és directament proporcional al nombre de RT rebuts».
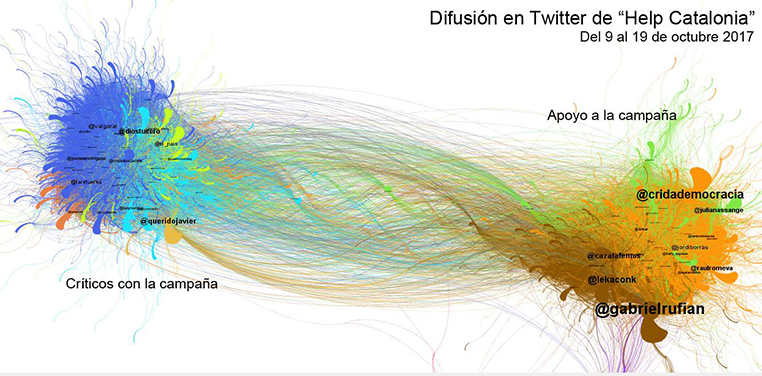
Font: http://www.barriblog.com/2017/10/hilo-difusion-la-campana-help-catalonia-twitter/.
Per fer-ho, hem d’explicar el graf o els grafs resultants i acompanyar-los de tots aquests elements. També hem d’afegir-hi documentació sobre com s’han obtingut les dades i com s’han realitzat els gràfics. Si has capturat dades d’un període de temps llarg, és possible que necessitis realitzar diferents grafs segons les fases de propagació de l’etiqueta.
Pots usar els filtres que ofereix Gephi per mostrar les diferents categories (modularity) que s’usen per acolorir els gràfics. Això et permetrà analitzar la composició d’aquestes xarxes i analitzar de què parla cadascuna d’elles. Aquest tipus de filtres permet activar només els usuaris d’una o més categories.
Pas a pas:
- Tria un títol.
- Escriu un paràgraf explicatiu/introductori.
- Afegeix gràfics que l’acompanyin.
Per a cadascun dels grups detectats (modularity) podem calcular les paraules més usades (bigrames i trigrames) amb databasic.io i/o utilitzar-les per fer un rànquing o un núvol. T-hoarder també ofereix la possibilitat de calcular les paraules més populars amb l’opció 7. Processing tweets (Entities). A partir de llista de tuits, les paraules associades a cada grup poden ajudar a entendre el graf:
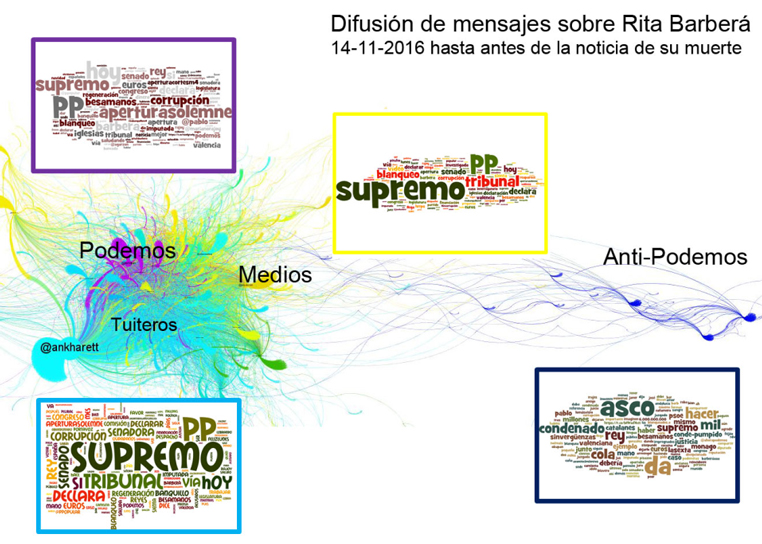
Font: http://www.barriblog.com/2016/11/despues-la-muerte-rita-barbera-twitter/.
Exemples d’anàlisis amb aquesta metodologia:
- Així es es va fer viral Tabarnia a les xarxes socials. Mariluz Congosto, 2018.
- Difusió de la campanya «Help Catalonia» en Twitter.
Nota
Pots descarregar el .gdf per replicar aquest exercici:
6.1.4.2. Com es relacionen els seguidors d’un compte de Twitter?
a. Quina anàlisi o visualització respon a la pregunta?
Un graf.
b. Quines dades necessito i on les puc trobar?
Crea un llistat amb els usuaris que han publicat una etiqueta determinada (pregunta anterior): com s’obté aquesta llista? Amb l’opció 7.Processing tweets i usant les opcions entity (que extreu els usuaris més repiulats, els més esmentats i els més actius), T-hoarder_kit et permet obtenir un fitxer amb la llista d’usuaris. Cal netejar el fitxer generat, ja que té altres variables associades i el que necessitem és un fitxer amb cada nom d’usuari en una línia. El següent pas consisteix a obtenir els perfils (profiles) d’aquests usuaris: 2.Get users information, escriu l’opció profile. Això genera un arxiu amb el nom xxxxx_profiles.txt que conté tots els perfils.
A partir d’aquesta llista de perfils es poden calcular les seves relacions (follower–following). Atenció: a l’hora d’obtenir els followers-following de cada usuari, l’API els proporciona a una velocitat de 60 usuaris cada hora. Per tant, trigarem 16,6 hores a per analitzar la relació entre 1.000 usuaris. Amb l’arxiu .gdf que hem generat passem al següent pas. Per tant, abans de començar a veure les relacions entre un grup d’usuaris d’una etiqueta determinada, podem seleccionar els usuaris segons un criteri (activitat o rellevància) per fer llistes d’usuaris més petites i, per exemple, estudiar com estan relacionats els 100 usuaris més esmentats o els 100 usuaris més actius.
Has de fer un graf de relacions declarades (following i followers entre els usuaris de l’etiqueta).
c. Quines eines de d’utilitzar per preparar les dades?
No aplicable. L’arxiu .gdf que has generat ja és vàlid per al següent pas.
d. Quines eines he d’utilitzar per crear l’anàlisi o la visualització?
Per generar el graf seguim el procediment descrit en l’exercici anterior, amb la diferència que ara tindrem molts menys nodes que en un graf de RT. El layout Forceatlas funciona millor per a menys nodes que el Forceatlas2.
e. Com presento la informació per fer un relat intel·ligible?
De la mateixa manera que a l’exercici anterior.
Exemple d’anàlisi amb una metodologia similar
- Digital Humanities on Twitter, a small-world? Martin Grandjean, 2015.
- Gregorio Morán, una columna vacía. Mariluz Congosto, 2017.
Pots descarregar el .gdf amb les relacions entre usuaris per replicar l’exercici: gregoriomoran_users_profiles.gdf.